
ConcurentHashMap解析
说明
ConcurrentHashMap并发容器
- 采用 cas自旋、while/for死循环、sychronize锁三种方式保证线程竞争下的插入安全,其原理与HashMap并不相同,改动量比较大
- jdk7采用分段segament的概念,把数组分为几段,每次锁一段达到并发的目的,但是分段会多维护一次hash
- jdk8采用锁数组的节点Node,将链表或红黑树整个锁定,达到线程安全。jdk8的精髓就在于没有node节点的时候数据的并发插入,它并没有阻塞线程,而是cas重试
源码解析
Jdk8源码
putValue()
1 | final V putVal(K key, V value, boolean onlyIfAbsent) { |
initTable()
核心就是循环判断tab容量
判断是否有其他线程已经开始了,有则放弃时间片进入下一次循环
没有则通过原子类获取执行权并设置sc为-1
初始化数组,初始化阈值
1 | private final Node<K,V>[] initTable() { |
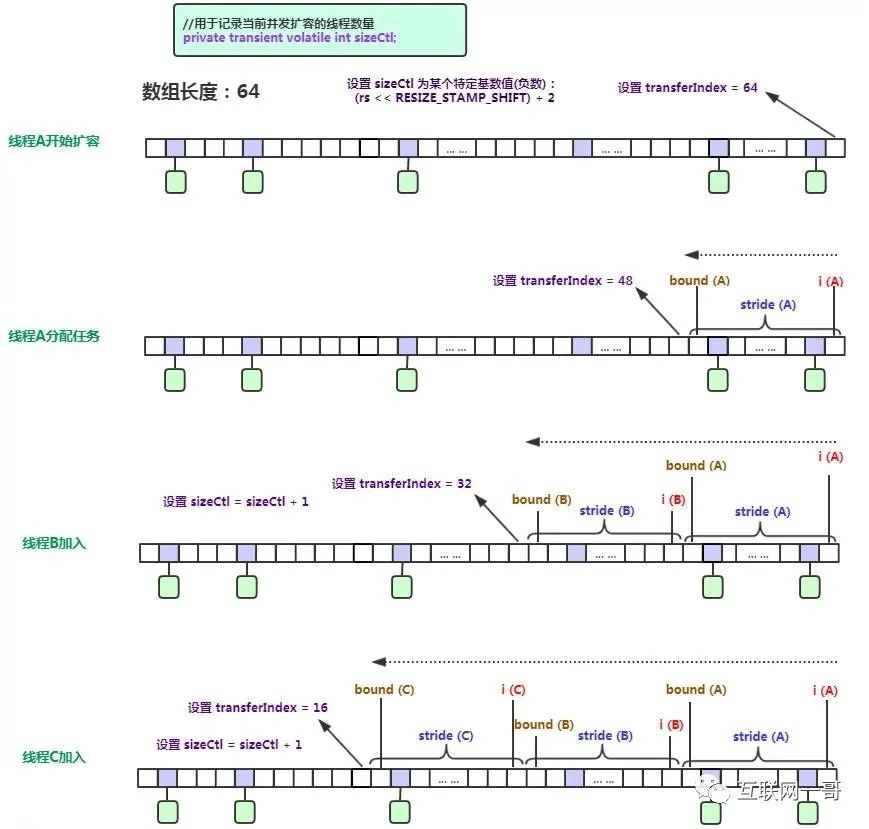
helpTransfer()
- 根据 CPU 核心数确定每个线程负责的桶数,默认每个线程16个桶
- 创建新数组,长度是原来数组的两倍
- 分配好当前线程负责的桶区域 [bound, nextIndex)
- 并发迁移,根据链表和红黑树执行不同迁移策略
- 迁移完成,设置新的数组和新的扩容阈值
1 | final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { |
扩容图文
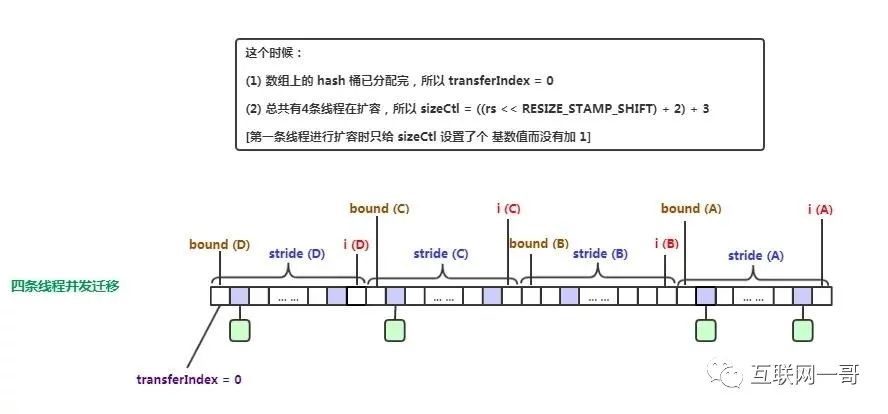
多线程开始扩容{}
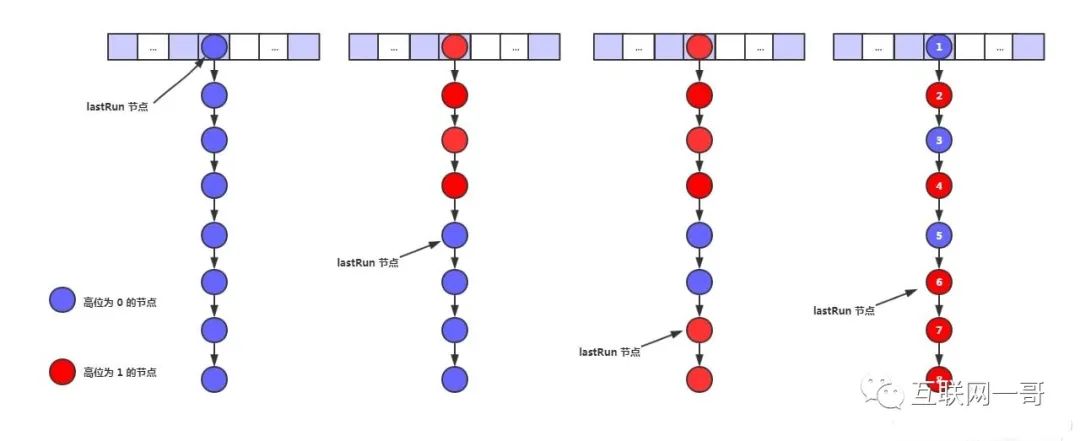
lastrun节点{}
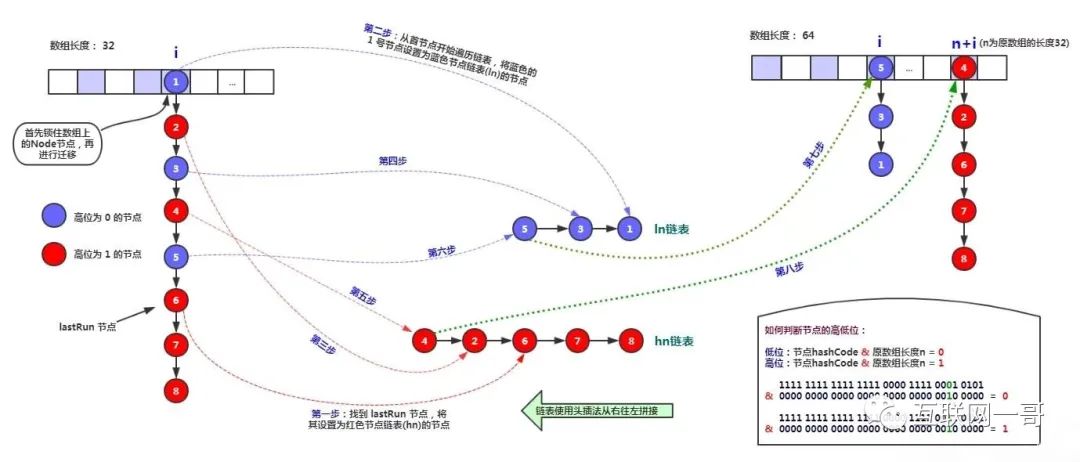
链表迁移{}
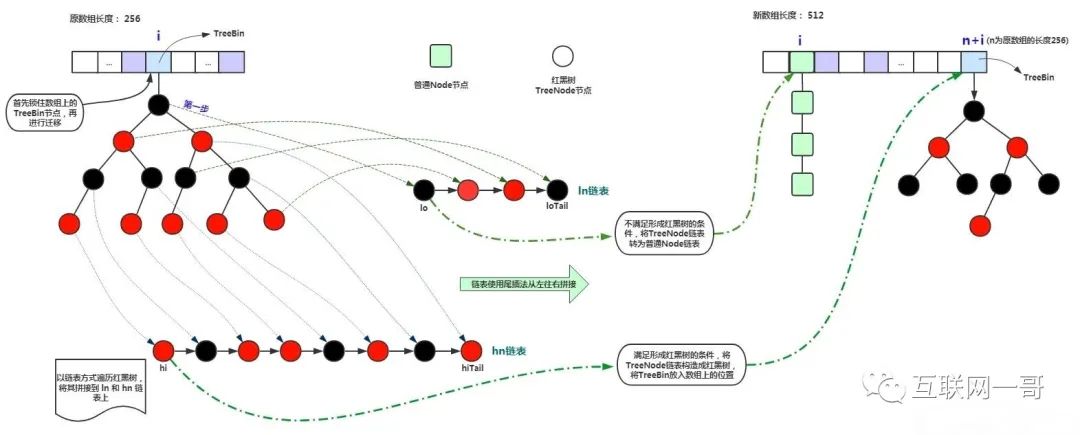
红黑树迁移{}
迁移过程中get和put的操作的处理{}
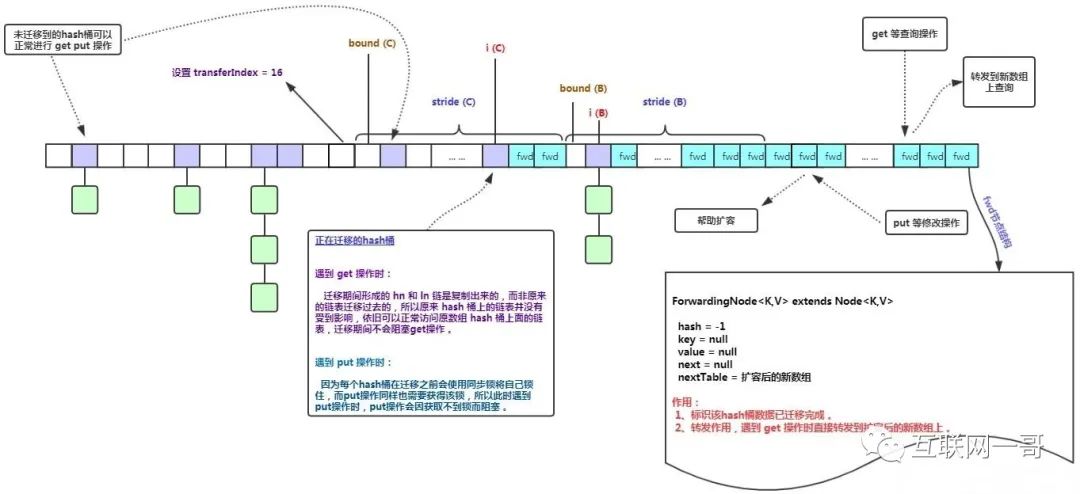
并发迁移{}
迁移完成{}
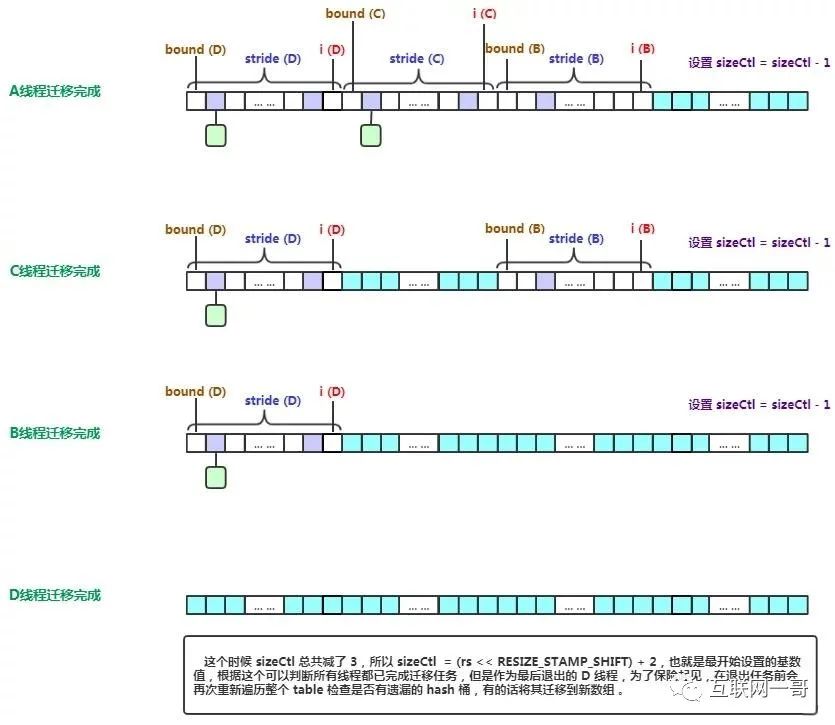
emm 引用至哪里,有点忘了,抱歉
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 KewenBlogs!
相关推荐

2023-07-07
HashMap解析
说明 底层采用数组+链表的数据结构存储 默认初始16容量,每次扩容2倍,加载因子0.75(即到了最大容量的0.75倍就开始扩容,因为过大的时候hash碰撞严重 自定义容量会按照向上取最近2^n数量定义初始容量,如new...
2023-07-07
反射
1. 反射定义2. 反射方法2.1. 获取集合对象中泛型的类型[^获取集合对象中泛型的类型] 泛型的概念 泛型概念 泛型:参数化类型,也就是说要操作的数据一开始不确定是什么类型,在使用的时候,才能确定是什么类型,把要操作的数据类型指定为一个参数,在使用时传入具体的类型,实现代码的模板化。 获取集合泛型时遇到的问题 在学习JDBC设计BaseDao<T>时类遇到了一个需要在创建子类对象时给父类BaseDao<T>赋上泛性类型的案例,具体代码实现如下 12345678910111213141516171819public class BaseDao<T> { private QueryRunner queryRunner = new QueryRunner(); // 定义一个变量来接收泛型的类型 private Class<T> type; // 获取T的Class对象,获取泛型的类型,泛型是在被子类继承时才确定(难点!!!) public BaseDao() { ...
2024-01-25
Classloader加载外部jar
1. 问题项目中依赖一个Jar,同时有一个地方又依赖这个Jar的早期版本的某方法或者某类等,如果不依赖上这个早期版本的话可能造成代码错误,调用不到指定的方法;但是如果依赖了这个早期版本,两个版本都在项目中大概率会造成无法启动,冲突;为了解决这个问题,我们便需要将局部地方依赖的早期jar作为局部使用的依赖传入项目供使用这需要知道ClassLoader的工作原理并正确的加载 如我项目中调用一个早期版本的Test1类 123<groupId>com.kewen.demo</groupId><artifactId>D0-Simple</artifactId><version>1.0-SNAPSHOT</version> 123456public class Test1 { public void hello(String a1,String a2){ System.out.printf("a1+a2 = "+a1+a2); //处理逻辑 ...
评论