1. 目录
[TOC]
2. 说明
在基于xml的spring项目中,前面分析BeanDefinition加载中已经说到,解析代码中的注解@Component需要在配置文件中配置<context:component-scan/>,然后在解析标签时扫描包中的注解,并加入BeanDefinition中。
3. 依赖关系
4. 源码解析
源码解析从获取ContextNameSpaceHandler开始
4.1. ContextNameSpaceHandler 来源
XmlReaderContext创建时会传入NamespaceHandlerResolver,NamespaceHandlerResolver便含有ContextNameSpaceHandler,代码如下
1
2
3
4
5
6
7
8
9
| public XmlReaderContext(
Resource resource, ProblemReporter problemReporter,
ReaderEventListener eventListener, SourceExtractor sourceExtractor,
XmlBeanDefinitionReader reader, NamespaceHandlerResolver namespaceHandlerResolver) {
super(resource, problemReporter, eventListener, sourceExtractor);
this.reader = reader;
this.namespaceHandlerResolver = namespaceHandlerResolver;
}
|
再往前看,创建XmlReaderContext是在XmlBeanDefinitionReader中,创建代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public XmlReaderContext createReaderContext(Resource resource) {
return new XmlReaderContext(resource, this.problemReporter, this.eventListener,
this.sourceExtractor, this, getNamespaceHandlerResolver());
}
public NamespaceHandlerResolver getNamespaceHandlerResolver() {
if (this.namespaceHandlerResolver == null) {
this.namespaceHandlerResolver = createDefaultNamespaceHandlerResolver();
}
return this.namespaceHandlerResolver;
}
protected NamespaceHandlerResolver createDefaultNamespaceHandlerResolver() {
ClassLoader cl = (getResourceLoader() != null ? getResourceLoader().getClassLoader() : getBeanClassLoader());
return new DefaultNamespaceHandlerResolver(cl);
}
|
最后我们得知创建了一个默认的解析器,而这个默认的解析器创建如下
1
2
3
4
5
6
7
8
9
10
11
12
|
public DefaultNamespaceHandlerResolver(@Nullable ClassLoader classLoader) {
this(classLoader, DEFAULT_HANDLER_MAPPINGS_LOCATION);
}
public DefaultNamespaceHandlerResolver(@Nullable ClassLoader classLoader, String handlerMappingsLocation) {
Assert.notNull(handlerMappingsLocation, "Handler mappings location must not be null");
this.classLoader = (classLoader != null ? classLoader : ClassUtils.getDefaultClassLoader());
this.handlerMappingsLocation = handlerMappingsLocation;
}
|
我们需要的ContextNamespaceHandler是在spring-context依赖下,内容如下
1
2
3
4
5
| http\://www.springframework.org/schema/context=org.springframework.context.config.ContextNamespaceHandler
http\://www.springframework.org/schema/jee=org.springframework.ejb.config.JeeNamespaceHandler
http\://www.springframework.org/schema/lang=org.springframework.scripting.config.LangNamespaceHandler
http\://www.springframework.org/schema/task=org.springframework.scheduling.config.TaskNamespaceHandler
http\://www.springframework.org/schema/cache=org.springframework.cache.config.CacheNamespaceHandler
|
这样就可以获取到ContextNamespaceHandler,ContextNamespaceHandler下的解析器parsers主要包括以下:
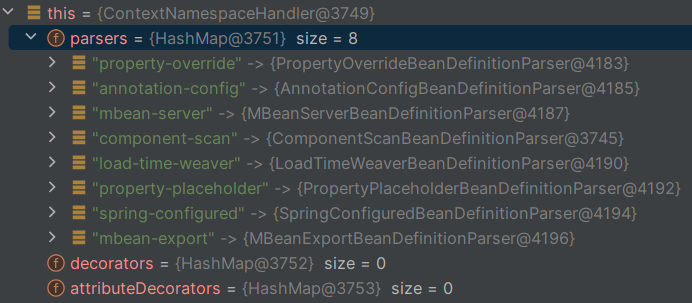
可以看出,我们需要的@Configuration,@ComponentScan等注解都在这里解析
4.2. ContextNamespaceHandler#parse()解析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
@Override
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
BeanDefinitionParser parser = findParserForElement(element, parserContext);
return (parser != null ? parser.parse(element, parserContext) : null);
}
@Nullable
private BeanDefinitionParser findParserForElement(Element element, ParserContext parserContext) {
String localName = parserContext.getDelegate().getLocalName(element);
BeanDefinitionParser parser = this.parsers.get(localName);
if (parser == null) {
parserContext.getReaderContext().fatal(
"Cannot locate BeanDefinitionParser for element [" + localName + "]", element);
}
return parser;
}
|
对于<context:component-scan/>标签拿到的则为ComponentScanBeanDefinitionParser
@Configuration则为其他的
4.3. @ComponentScan的解析
前面已经调用到parse方法,则直接从parse开始
4.3.1. ComponentScanBeanDefinitionParser#parse()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public BeanDefinition parse(Element element, ParserContext parserContext) {
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
}
|
4.3.2. ClassPathBeanDefinitionScanner#doScan()执行扫描
执行扫描,重点在scanCandidateComponents()中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
protected void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry) {
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, registry);
}
|
扫描出的类示例 Resource[] resources:
4.3.3. BeanDefinitionReaderUtils#registerBeanDefinition() 注册到Register中
此静态方法专门用于设置,其实此类里面逻辑较为简单,两个方法
- 注册成BeanDefinition
- 添加别名alias
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
|
4.3.4. DefaultListableBeanFactory#registerBeanDefinition()注册方法
这已经又到了BeanFactory类了,因此,我们这里就是把解析的BeanDefinition加载到BeanFactory中了,前面的扫描封装逻辑结束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
if (existingDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition);
}
else if (existingDefinition.getRole() < beanDefinition.getRole()) {
if (logger.isInfoEnabled()) {
logger.info("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
existingDefinition + "] with [" + beanDefinition + "]");
}
}
else if (!beanDefinition.equals(existingDefinition)) {
if (logger.isDebugEnabled()) {
logger.debug("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
removeManualSingletonName(beanName);
}
}
else {
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
removeManualSingletonName(beanName);
}
this.frozenBeanDefinitionNames = null;
}
if (existingDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
else if (isConfigurationFrozen()) {
clearByTypeCache();
}
}
|
加载BeanDefinition到Map中后则成功走完了BeanDefinition加载逻辑。待后续使用了,此部分结束;
5. 总结
spring在这里利用了SPI机制加载了 ContextNameSpaceHandler,里面含有配置ComponentScanBeanDefinitionParser,它在扫描注解<context:component-scan/>时直接通过ComponentScanBeanDefinitionParser开始处理@Component,
在ComponentScanBeanDefinitionParser中主要通过转换路径,然后通过ClassPathBeanDefinitionScanner创建资源,扫描包路径下的类,找到@Component对应的类,并通过类BeanDefinitionReaderUtils静态方法注册BeanDefinition到BeanDefinitionRegistry即BeanFactory中
6. 注意要点

